






















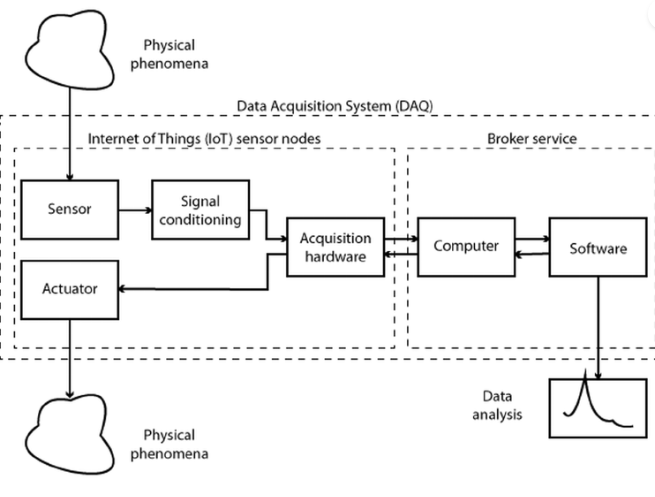
In the world of data science, the foundation for extracting meaningful insights lies in the data itself. However, acquiring relevant and high-quality data is a crucial initial step that can significantly impact the success of any data-driven project. In this blog, we will explore the data acquisition process in data science, highlighting its importance and providing a comprehensive guide to help you navigate through this critical stage. Additionally, we will introduce some popular libraries commonly used for data acquisition. So, let’s dive in!
Understanding Data Acquisition
Data acquisition refers to the process of gathering, collecting, and preparing data for analysis. It involves identifying the data sources, extracting the required data, transforming it into a suitable format, and loading it into a storage system for further processing. Effective data acquisition ensures that the data used in analysis is accurate, reliable, and relevant to the problem at hand.


Identifying Data Sources
The first step in the data acquisition process is identifying the data sources. These sources can be diverse, including structured databases, unstructured text documents, APIs, web scraping, log files, social media platforms, or even IoT sensors. Understanding the nature and characteristics of the data sources is crucial for selecting the appropriate data acquisition techniques.
Data Extraction
Once the data sources are identified, the next step is to extract the data. Various techniques can be used for data extraction, depending on the source. Let’s explore some popular libraries that can assist in data extraction:
a. Pandas:
- Reading Data: Pandas provides intuitive functions to read data from a wide range of file formats, including CSV, Excel, JSON, SQL databases, and more. The
read_csv()function, for example, allows you to load data from a CSV file into a Pandas DataFrame. Similarly,read_excel()enables importing data from Excel files. Pandas ensures data integrity during the loading process, handling different data types, and automatically inferring column types. - Handling Data Structures: Once the data is loaded into a Pandas DataFrame, it can be easily manipulated and transformed. Pandas offers a rich set of methods to clean, filter, aggregate, merge, and reshape the data. You can handle missing values, apply data transformations, and perform data quality checks using Pandas’ built-in functions. This flexibility allows for efficient data preparation and ensures the data is in a suitable format for analysis.
- Integrating with Data Sources: Pandas can seamlessly connect to various data sources, including SQL databases. By utilizing libraries like SQLAlchemy, Pandas can execute SQL queries directly on the database and retrieve the results as a DataFrame. This enables data scientists to leverage their SQL skills while benefitting from Pandas’ powerful data manipulation capabilities.
- Combining Multiple Data Sources: With Pandas, you can merge and join data from different sources based on common keys or indices. This functionality is useful when dealing with data spread across multiple files or databases. Pandas simplifies the process of combining datasets, allowing for a comprehensive analysis of interconnected data.
b. Beautiful Soup: Beautiful Soup is a Python library used for web scraping. It helps extract data from HTML and XML files by parsing the markup structure of web pages. Beautiful Soup simplifies the process of navigating and searching for specific elements within the web page.
c. Requests: Requests is a versatile Python library that simplifies the process of sending HTTP requests and interacting with web APIs (Application Programming Interfaces). It offers a wide range of functionalities to retrieve data from web services, handle authentication, headers, and query parameters. Here’s an expanded overview of how Requests is used for data acquisition:
- Sending HTTP Requests: Requests allows you to send various types of HTTP requests, including GET, POST, PUT, DELETE, and more. These requests are used to communicate with web servers and retrieve or modify data. With a straightforward and intuitive interface, you can specify the request type, URL, headers, parameters, and data payload.
- Handling Authentication: Many web services require authentication before granting access to their data. Requests simplifies the process of handling authentication by providing mechanisms to include authentication credentials, such as API keys or tokens, in your requests. You can easily add authentication parameters to your requests to authenticate with the server and access protected resources.
- Managing Headers and Parameters: Requests allows you to customize the headers of your HTTP requests. Headers can include information such as the user agent, content type, and authorization details. You can set these headers as needed to comply with API requirements or to retrieve specific data formats. Additionally, Requests provides the ability to include query parameters in the URL to refine your data requests and retrieve specific subsets of data.
- Handling Response Data: Once a request is made, Requests handles the server’s response, which typically includes data in various formats such as JSON, XML, or plain text. Requests provides convenient methods to access and parse the response data based on its format. For example, if the response is in JSON format, you can use the
.json()method to parse the JSON data into a Python dictionary or list for further processing. - Error Handling and Status Codes: Requests automatically handles common HTTP errors and status codes, making it easy to handle different response scenarios. It raises exceptions for common errors such as connection timeouts, server errors, or invalid requests. You can use these exceptions to handle errors gracefully and ensure the reliability of your data acquisition process.
- Session Management: Requests supports the concept of sessions, allowing you to persist certain parameters across multiple requests. Sessions can be helpful when interacting with APIs that require maintaining a state, such as managing cookies or establishing persistent connections.
- Integration with Data Analysis: Once the data is retrieved using Requests, you can further process and analyze it using other libraries such as Pandas or NumPy. By leveraging the data acquisition capabilities of Requests, you can incorporate data from various web services and APIs into your analysis pipelines
d. Selenium: Selenium is a widely used library for web scraping and browser automation in the field of data acquisition. It offers a robust and flexible framework for interacting with web pages, handling dynamic content, and simulating user interactions. Here’s an expanded overview of how Selenium is utilized for data acquisition:
- Web Scraping and Data Extraction: Selenium is primarily employed for web scraping tasks that involve extracting data from web pages. It allows you to programmatically control web browsers and navigate through web pages, making it possible to extract data that is rendered dynamically through JavaScript or AJAX calls. This is particularly useful for acquiring data from websites that heavily rely on client-side rendering.
- Dynamic Web Content Handling: Many modern websites utilize JavaScript to load or modify content dynamically. Unlike static HTML content, this dynamic content cannot be easily accessed using traditional parsing libraries. Selenium overcomes this limitation by executing JavaScript code within the browser, thus rendering the dynamic content and making it accessible for data extraction. This enables data scientists to retrieve the complete and up-to-date information available on a web page.
- User Interactions and Form Submissions: Selenium enables the simulation of user interactions with web pages, such as clicking buttons, filling out forms, or submitting data. This feature is particularly useful when acquiring data that requires navigating through multiple pages or performing specific actions to access the desired information. Selenium automates these interactions, mimicking the behavior of a user, and retrieves the data accordingly.
- Multiple Browser Support: Selenium supports multiple web browsers, including Chrome, Firefox, Safari, and Internet Explorer, allowing you to choose the browser that best suits your needs. It provides drivers for each supported browser, which act as a bridge between Selenium and the browser, enabling seamless automation and data extraction.
- Headless Mode: Selenium also offers a headless mode, where the browser runs in the background without a graphical user interface. This mode is particularly useful for executing automated scraping tasks in server environments or when a visual representation of the browser is not required. Headless mode enhances performance and resource utilization while allowing data acquisition to take place in the background.
- Integration with Other Libraries: Selenium can be integrated with other libraries and tools, such as Beautiful Soup or Pandas, to enhance the data acquisition process. Beautiful Soup can be used in conjunction with Selenium to parse the retrieved HTML content and extract the desired data. Pandas can then be utilized to perform data manipulation and analysis on the acquired data, enabling seamless integration with the rest of the data science workflow.
Data Transformation
Data acquired from different sources may have varying formats, structures, and quality. Therefore, it is crucial to transform the data into a consistent format suitable for analysis. Data transformation involves tasks such as cleaning, filtering, aggregating, merging, and reshaping the data. Here are a few libraries that facilitate data transformation:
a. NumPy: NumPy is a fundamental library for scientific computing in Python. It provides a powerful N-dimensional array object, which enables efficient numerical operations on large datasets. NumPy’s functions for array manipulation and mathematical operations are valuable during the data transformation process.
b. Pandas: As mentioned earlier, Pandas offers extensive functionality for data manipulation. It provides powerful tools for handling missing data, data alignment, filtering, grouping, and merging datasets. Pandas also allows for the creation of derived features, which can enhance the analysis.
c. OpenRefine: OpenRefine (formerly Google Refine) is an open-source tool for data cleaning and transformation. It simplifies the process of exploring and cleaning messy datasets. OpenRefine provides an intuitive interface to perform operations such as data type conversion, standardization, deduplication, and text manipulation.
Data Loading
Once the data is extracted and transformed, it needs to be loaded into a suitable storage system for further analysis. The choice of storage depends on factors like data volume, accessibility, scalability, and analysis requirements. Some commonly used storage systems include relational databases (e.g., MySQL, PostgreSQL), NoSQL databases (e.g., MongoDB, Cassandra), data lakes (e.g., Apache Hadoop, Amazon S3), and cloud-based platforms (e.g., Google BigQuery, Amazon Redshift).
Data acquisition is a fundamental stage in the data science workflow that lays the groundwork for successful analysis and insights generation. By understanding the data sources, using appropriate extraction techniques, transforming the data effectively, and choosing suitable storage systems, data scientists can ensure the availability of high-quality data for analysis. Libraries such as Pandas, Beautiful Soup, Requests, Selenium, NumPy, and OpenRefine provide powerful tools to simplify and streamline the data acquisition process. Remember, investing time and effort in acquiring reliable data sets the stage for meaningful analysis and impactful outcomes in the world of data science.
Watch this Youtube video for more practical understanding data acquisition process.
Reference
Design of the Data Acquisition System Based on STM32 – ScienceDirect
Read also…


















{kind=link}
Discussion about this post